Business Intelligence & Data Science
Daten sichtbar und verständlich machen
Alles andere als eine Rocket Science
Wir unterstützen Sie dabei, die Vorteile der Digitalisierung voll auszuschöpfen! Dabei ist es umso wichtiger mehr Erkenntnisse, Entscheidungen und Möglichkeiten aus den vorhandenen Daten zu ziehen. Hierbei kommt es besonders darauf an, die richtigen Daten zu erfassen und diese so aufzubereiten, dass damit verlässliche Auswertungen und Analysen möglich sind.
Daten, das digitale Gold
Jeden Tag werden in Unternehmen Daten generiert, ob in der Entwicklung, der Produktion, der Buchhaltung oder dem Kundenverhalten. Gerade in der heutigen Zeit steigt die Menge der Daten enorm, aus welchen sich allerdings wichtige Erkenntnisse schöpfen lassen. Gerade oder besonders deshalb werden Daten auch das "digitale Gold" genannt. Denn wenn man die Daten korrekt erfasst und hervorragend aufbereitet, können aus deren Auswertung entscheidende Hinweise für die strategische Ausrichtung Ihres Unternehmens gewonnen werden. Unternehmen, welche die Datenerfassung und -analyse priorisieren, schneiden tendenziell besser ab als solche, die dies nicht tun. Analysen von qualitativen und quantitativen Daten helfen zu verstehen, warum Situationen passiert sind, wie Probleme behoben werden und was Sie in Zukunft erwarten können.
Wir unterstützen Sie dabei:
- Daten zu sammeln
- gesammelte Daten aufzubereiten
- aufbereitete Daten zu visualisieren
Dadurch können Sie:
- Wissen aus Daten ziehen
- Handlungsempfehlungen ableiten
- Ihre Entscheidungsfindung unterstützen
- Unternehmensprozesse optimieren und automatisieren
- wirtschaftlicher arbeiten und Kosten reduzieren
- Ihre Unternehmenssteuerung unterstützen
- Prognosen erstellen um zukünftige Ereignisse vorhersagen.

Business Intelligence (BI) oder Data Science?
Was ist eigentlich der Unterschied zwischen Business Intelligence, kurz BI und Data Science? Im Wesentlichen unterscheiden sich die beiden Begriffe in der Verwendung der vorhandenen Daten. Während bei BI die Daten betrachtet werden, um daraus die historische Performance eines Unternehmens zu analysieren, werden bei Data Science die vorhandenen Daten genommen, um daraus Schlüsse für die Zukunft zu ziehen. Es wird also versucht die zukünftige Performance eines Unternehmens vorherzusagen.
Erheben und Speichern
der Daten

Aufbereitung der Daten

Analyse der Daten

Visualisierung der Daten
Erheben und Speichern der Daten
Um Daten auswerten zu können, müssen sie erst einmal gesammelt werden. Dazu stehen diverse Techniken zur Auswahl, um die Daten aus verschiedenen Quellen gewinnen zu können. Sie können durch Umfragen erhoben, aus vorhandenen Systemen exportiert, von Webseiten geladen oder automatisiert ausgelesen werden.
Data Warehouse
Das Data Warehouse, kurz DWH ist das Herzstück eines jeden BI- und Analysesystems. Es handelt sich hierbei um ein Datenbanksystem, in welchem die erfassten Daten gespeichert und bereitgestellt werden. Das DWH ermöglicht eine globale Sicht auf eine große heterogene Menge von Daten sowie eine Strukturierung und Zusammenfassung der Daten. Es bildet somit die Grundlage für alle Analysen zur Entscheidungsfindung und garantiert dabei eine hohe Datenqualität.
Dies ist eine Übersicht der Architekturschichten, welche folgend erklärt werden:
Stage
Erste Ebene des DWH ist die Stage. Sie importiert und enthält die Daten in der Struktur wie das Quellsystem. Diese ist geteilt in zwei Unterschichten: Bei Staging werden neue oder geänderte Daten des Quellsystem in der Struktur des Quellsystem importiert. Daten werden nach erfolgreicher Verarbeitung gelöscht und bilden die Rohdatenquelle für den Operational Data Store. Die zweite Unterschicht ist der Operational Data Store, kurz ODS. Hier werden neue / geänderte Daten des SL-Layer importiert bzw. aktualisiert. ODS bildet die Rohdatenquelle für Computational Layer (CL) & Data Mart (DM) -Layer. Die Daten werden nicht gelöscht. Der Speicherbedarf steigt somit mit der Zeit. Sie dient der Integration von einer oder mehrerer Datenquellen.
Core
Der Core ist die zweite Ebene, der Kern und enthält Daten in verschiedenen Zuständen: Zwischenergebnisse im Entwicklungsstatus sowie fertige Daten für Auswertungen. Diese Schicht wird wiederum aufgeteilt in drei Unterschichten: Computational, Data Mart und Reporting.
Der Computational Layer (CL) lädt Daten aus dem ODS-Layer und kombiniert Daten aus verschiedenen ODS-Tabellen. Daten werden hinsichtlich ihrer Domänenzugehörigkeit integriert und transformiert. Redundanzen werden reduziert oder aufgelöst. Integritätseinschränkungen werden eventuell berücksichtigt. Daten im CL können Datenprobleme des Quellsystem enthalten, also falsche, unvollständige, inkonsistente und widersprüchliche Daten. Die Daten werden in dieser Schicht modelliert, strukturiert, optimiert und indiziert für die weitere Verarbeitung.
Der Data Mart Layer (DM) lädt Daten aus dem ODS- und CL-Layer. Diese Daten sind hier „sauber“ und enthalten keine falschen, unvollständigen, inkonsistenten und widersprüchlichen Informationen. Die aufbereiteten Daten werden für das Reporting bereitgestellt. Zusätzlich findet hier die schwerpunktspezifische Aufteilung der Daten in Domänen statt und bieten somit einen effizienten und performanten Zugriff.
Das Reporting Layer bietet aufbereitete Daten in Views oder Tabellen sowie die Bereitstellung von Kennzahlen bspw. per SSAS. Die Daten werden in Data Marts unterteilen, welche nach Themenschwerpunkten und Data Interfaces für Systeme geclustert werden.
Mart
In dieser letzten Ebene sind die Daten bereit zur Auswertung. Die Datenstruktur, -qualität und -beschaffenheit sind abteilungs- oder lösungsspezifisch bereitgestellt. Diese Ebene überschneidet sich bei den Layern DM und Reporting mit der Core-Ebene, da die Daten an dieser Stelle schon bereit zur Auswertung sind und somit abgegriffen werden können. Erweitert wird der Mart noch um den Layer Solution. Hier werden die Daten in Form von Kennzahlen und Hierarchien über bspw. den SQL-Server Analysis Service bereitgestellt.
Weitere Speichermöglichkeiten
Data Lake
Eine weitere Option der Datenerhebung ist der Data Lake (dt. „Datensee“), welcher ein sehr großer Datenspeicher ist und vielmehr zur Speicherung aller Strukturen aus unterschiedlichsten Quellen in ihrem Rohformat verwendet wird. Er kann sowohl unstrukturierte als auch strukturierte Daten enthalten und lässt sich aufgrund dessen für Big-Data-Analysen sehr gut einsetzen. Ein Data Lake besitzt dabei die Fähigkeit Daten aus einer Vielzahl von Quellen, ob von internetfähigen Geräten, Social-Media-Kanälen, Benutzerdaten oder Transaktionen von Webanwendungen aufzunehmen. Er bietet somit eine kostengünstige Speicherung großer Datenmengen aus vielen Quellen. Denn das Zulassen von Daten beliebiger Struktur reduziert die Kosten, da Daten flexibler und skalierbarer sind und nicht in ein bestimmtes Schema passen müssen.
Data Hub
Ein Data Hub ist eine Datensammlung, in der unterschiedliche Daten zusammengefasst werden, die wiederum für die Verteilung und gemeinsame Nutzung organisiert sind, ohne dass dafür ein Daten-Zentrallager erforderlich ist. Es besitzt dabei eine datenzentrierte Storage-Architektur, die Unternehmen bei der Konsolidierung und dem Austausch von Daten unterstützt. Dazu werden spezielle Pipelines eingerichtet. Der Zugriff und die Verarbeitung erfolgt dann direkt am Ablageort. Ein Data Hub kann als Hub-and-Spoke-Ansatz zum Speichern und Verwalten von Daten betrachtet werden. Indem Sie Ihre Infrastruktur in einen Data Hub konvertieren, können Sie also den Datenfluss über Ihr Unternehmen deutlich optimieren..
Aufbereitung der Daten
Der wichtigste Schritt, bevor Sie Informationen aus den Daten gewinnen können, ist die Aufbereitung der Daten. Hierbei kommt es darauf an, die Daten so zu verarbeiten, dass Sie, als Unternehmen daraus die richtigen Schlüsse ziehen können.
ETL (Extract Transport Load) - Prozess
ETL steht für Extrahieren, Transformieren und Laden. Es ist ein Prozess, bei dem Daten aus mehreren, gegebenenfalls unterschiedlich strukturierten Datenquellen in einer Zieldatenbank vereinigt werden.
- Der erste Schritt der ETL-Architektur heißt Extraktion und beschreibt das Herausziehen von Daten aus einer Datenquelle. Diese werden während dieser Phase gelesen und gesammelt, oft aus zahlreichen Quellen, wie z. B. On-Premise- und Cloud-Datenbanken, Unternehmensanwendungen, Dateisystemen etc.
- Während der Transformation, werden die extrahierten Daten aus dem ersten Schritt in ein Format für eine andere Datenbank konvertiert. Die Datentransformation erfolgt in dieser Phase mithilfe von Ausdrücken, Regeln, Nachschlagetabellen oder durch Zusammenführen von zwei oder mehr Datensätzen.
- Der letzte Schritt ist das Laden, dass die Daten in die Zieldatenbank, das Data Warehouse oder andere Speichermöglichkeiten schreibt.
Die folgende Grafik visualisiert die verschiedenen Prozessschritte:
Analyse der Daten
Analyse mithilfe von SSAS – SQL Server Analysis Service
SQL Analysis Services – kurz: SSAS – basiert auf Microsoft-SQL und ist eine wichtige Komponente von modernen BI-Systemen. Es ist ein analytisches Datenmodell, welches zur Entscheidungsunterstützung und Geschäftsanalyse dient. Es bietet semantische Datenmodelle auf Unternehmensniveau durch tabellarische oder mehrdimensionale Auswertungen von Daten. Diese Ergebnisse helfen bei der Planung und Kontrolle in Bereichen wie Finance, Controlling, Vertrieb, Produktion sowie Personal und dienen der Verbesserung der Performance Ihres Unternehmens.
SSAS bietet in diesem Kontext zwei unterschiedliche Datenbank-Technologien: Multidimensionales Model und Tabularmodel
- Multidimensionales Model: Das multidimensionale Model ist die „klassische“ und bewährte Technologie. Multidimensionale Modelle sind immer noch die gängige Lösung bei großen Datenmengen, vielen Nutzern und hoher Komplexität. Sie verfügen über eine Vielzahl an Funktionalitäten, die hohe Komplexität macht das Modell aber auch weitestgehend untauglich für Self-Service BI.
- Tabularmodel: Tabularmodel ist eine relativ junge Technologie, die eine leistungsfähige Brücke von Excel / Power Pivot zur professionellen BI Serverapplikation im Rahmen einer Self-Service-BI Strategie bietet. Das Tabularmodel besteht aus einer relationalen Modellstruktur und stellt Dimensionen und Kennzahlen bereit. Im Vergleich zum multidimensionalen Modell ist es einfach zu entwickeln und verwalten. Der Einstieg in die Thematik ist wesentlich einfacher. Zwar bietet es weniger Funktionen, aber eine schnellere Datenverarbeitung und -kompression. Es eignet sich bis Größen von ca. 5 TB.
- Tabular Cube bezeichnet das Modell als Ganzes, unterteilt in Perspektiven. Schlüsselbegriffe sind hier: Dimension, Fact, Dimensional Model oder Star Schema.
Visualisierung der Daten
Daten bilden als Rohmaterial die Grundlage des Visualisierungsprozesses. Das Ziel besteht darin, aus den Daten Informationen zu gewinnen, denn Daten ohne Kontext sind für Entscheidungen wertlos.
Um Daten übersichtlich darzustellen gibt es verschiedenste Visualisierungsformen. Zwar zählen Tabellen auch dazu und werden häufig zur Datenanalyse und Präsentation eingesetzt, jedoch bilden sie die niedrigste Form der Veranschaulichung. Zusammenhänge der Daten können mit Tabellen nicht so einfach erkannt werden wie mit Diagrammen. Es gibt viele verschiedene Ansätze für die Visualisierung von Daten und alle haben eine gemeinsame Grundidee - ein durchdachtes Konzept. Unter dem Konzept ist eine systematische Beschreibung des Visualisierungsprozesses gemeint.
Ausrichtung der Visualisierung
Ein wesentliches Fundament für eine gute Visualisierung ist, dass der Zweck von Beginn an klar definiert ist, da eine ungeeignete Visualisierung viele Folgen mit sich trägt. So könnte eine schlechte Darstellung eine Fehlinterpretation oder sogar Fehlentscheidungen mit sich ziehen. Um dies zu vermeiden, sollte eine Visualisierung gründlich vorbereitet und die zu visualisierenden Inhalte geklärt werden.
Tableau
Tableau ist eine weltweit, marktführende BI- und Analyse-Software als Teil von Salesforce. Sie ermöglicht es, Daten zu verknüpfen und Informationen somit zu visualisieren, analysieren oder publizieren. Der Schwerpunkt der Software liegt somit auf der Datenanalyse und Datenvisualisierung.
Tableau bietet verschiedene Komponenten an. Tableau Desktop erlaubt das Verbinden und Kombinieren von vielen verschiedenen Datenquellen, so unterstützt Tableau von einer einfachen Textdatei oder ExcelListe bis hin zu Datenbanksystemen wie MySQL, SAP Hana oder Oracle - bis zu über 50 verschiedene Quellen jeder Art. Die Datenbank Engine eröffnet das direkte Arbeiten auf der Datenbank, ohne negative Auswirkungen auf die Produktivdatenbank zu haben, ist schnell und erlaubt somit Echtzeit-Datenanalysen. Die Anwendung erlaubt unter anderem mehrere Ansichten zu einem interaktiven Dashboard zu kombinieren und bietet damit Filter-, Drilldown- und Kommentarfunktion an. Zudem können auch Webseiten, Dokumente oder Bilder hinzugefügt werden. Die Ausgabe kann entweder statisch in Form eines PDFs oder einer Bilddatei erfolgen oder als interaktives Workbook innerhalb des Webinterface des Tableau Server.
Mit Tableau Server ist eine interaktive browserbasierte Ausgabe möglich, womit die Workbooks veröffentlicht und zum Austausch genutzt werden können. Dadurch können Workbooks auch über Smartphones und Tablets aufgerufen werden, Tableau optimiert dabei automatisch die Darstellung für das jeweilige Gerät. Auch lassen sich mit Tableau Server Benutzergruppen erstellen und Authentifizierungen verwalten, womit auch Zugriff und Berechtigungen auf die Daten und Inhalte gesteuert werden können.
Vorteile für Tableau?
- starke Visualisierungen
- intuitive Gestaltung
- Anschluss und Verknüpfung diverser Datenquellen
- Datensicherheit
- einfache Verwaltung
- umfangreiche Community
- ständige Weiterentwicklung
- Mobil oder Desktop
- Analyseupdates in Echtzeit
Power-BI
Power BI von Microsoft ist eine BI-Lösung, welche aus den zentralen Power BI Services für eine cloudbasierte Analyse von Geschäftsdaten zusammensetzt. Sie macht es möglich Unternehmen aller Branchen und Größen, Daten aus mehreren Quellen flexibel zu extrahieren und später in kreativen und interaktiven Berichten zu analysieren.
Power BI besteht aus verschiedenen Komponenten. Es handelt sich um unterschiedliche Services, Gateways und Tools, die teilweise in der Cloud bereitgestellt und teils auf Endgeräten betrieben werden. Mit Power BI Desktop für Windows ist es möglich, auf PCs oder Laptops Verbindungen mit Daten herzustellen, diese zu transformieren, abzufragen sowie zu modulieren und daraus umfassende Berichte zu erstellen. Die Ergebnisse sind über den Power BI Service mit anderen teilbar und leicht zu veröffentlichen. Die Power BI Apps sind für die mobile Verwendung auf Smartphones oder Tablets konzipiert.
Aufgrund der cloudbasierten Architektur sind Analysen von verschiedenen Geräten an beliebigen Orten in Echtzeit möglich. Ergebnisse können einfach veröffentlicht und mit anderen geteilt werden. Eine intuitive Bedienung und vordefinierte Dashboards gestatten einen schnellen Einstieg in die Business Intelligence ohne tiefere IT-Kenntnisse.
Vorteile für Power BI?
-
Niedrige Kosten
-
Mobil oder Desktop
-
hohe Benutzerfreundlichkeit in der gewohnten Microsoft 365 Erfahrung
- Beispiellose Excel-Interoperabilität
-
Integration und Automatisierung von Drittanbieterdaten
-
Vereinheitlichen von Self-Service- und Unternehmens-Analysefunktionen
-
Schnelle Antworten dank branchenführender KI
-
verbesserte Veröffentlichungsgeschwindigkeit und Genauigkeit für Power BI-Inhalte
-
Analyseupdates in Echtzeit Laufende Verbesserung
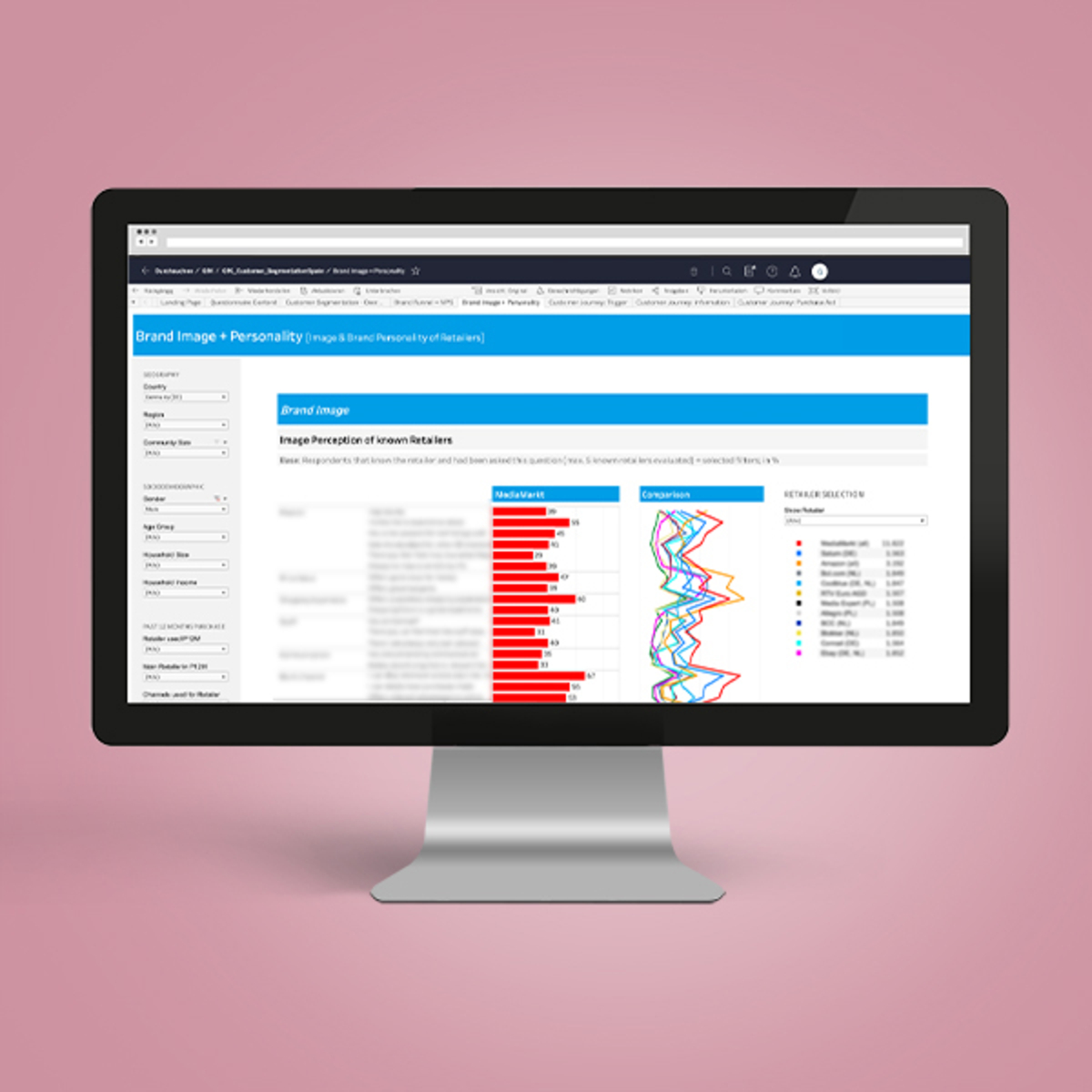
BI-Reports für eine Marktstudie
Der GfK-Bereich "Consumer Insights & Marketing Effectiveness Client Solutions DACH" benötigte Unterstützung bei der die Entwicklung von Tableau-Reports, d. h. für dynamische Auswertungen von Ergebnissen einer Marktstudie.

Get in Touch
Ihr Ansprechpartner
Jörg Meier
Vorstand, CEO
joerg.meier@mediendesign.de